
一 odoo + SANIC…应对高并发场景
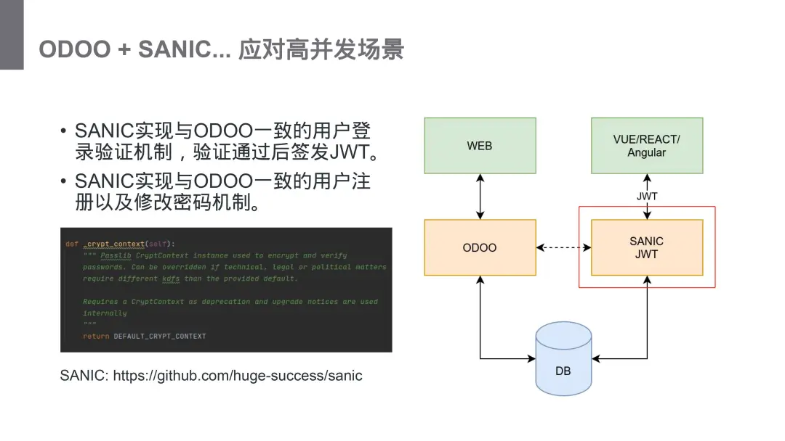
SANIC 实现与 odoo 一致的用户登录验证机制,验证通过后签发 JWT
SANIC 实现与 odoo 一致的用户注册及修改密码机制
二 odoo + Elasticsearch应对复杂搜索场景

odoo 增加 json 兼容的输出,用于 ES 索引发布
通过 odoo 定时任务定期更新索引
通过 odoo+Celery 或者 odoo 的 server action 准实时更新索引
三 odoo + Celery应对复杂长事务处理场景
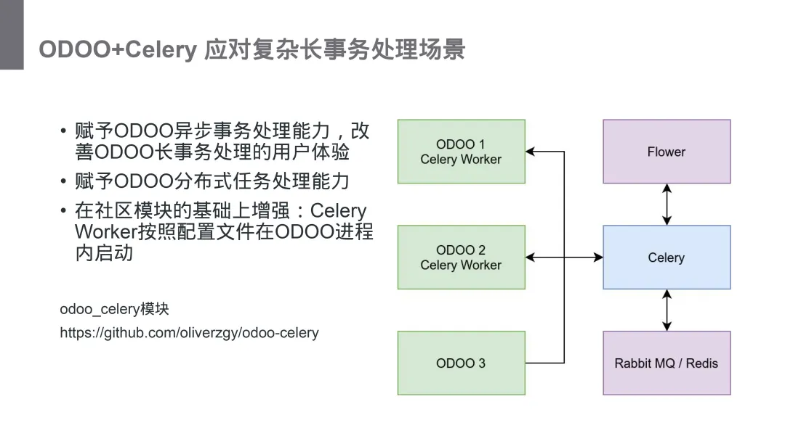
赋予 odoo 分布式任务处理能力
在社区模块的基础上增强:Celery Worker 按照配置文件在 odoo 进程内启动
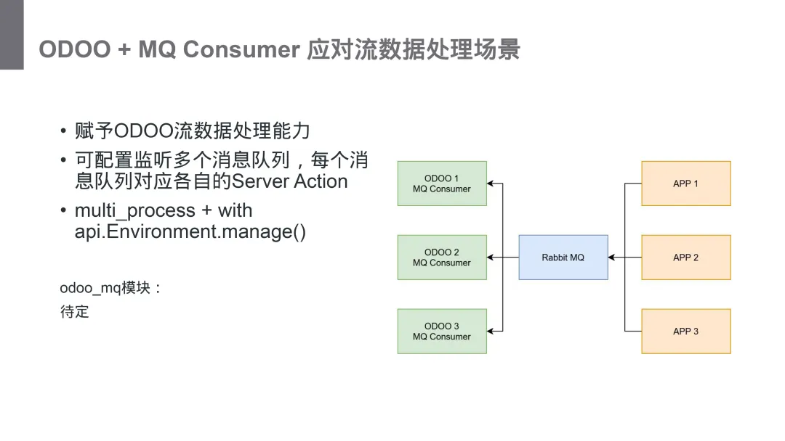
四 odoo + MQ Consumer应对流数据处理场景
五 odoo + Dgraph 应对复杂关系场景

六 odoo + Seaweeds 应对多文件,图片存储场景

Q & A(部分)
01
有专门配置权限的模块吗?
02
SANIC部署起来的难易程度如何?
03
SANIC在这里是API网关的概念吗?odoo作为web server?
04
对于odoo学习,对新手有什么建议吗?
往期推荐