2021年4月23日,新商科开放创新实验室筹备工作会议在上海对外经贸大学召开。本次会议由上海开源信息技术协会发起,来自SAP、IBM、华为、海尔CosmoPlat、Odoo香港、上海易路人力资源科技、法林瓦、上海西信信息、上海企通的企业代表,以及上海对外经贸大学、河南大学、济南大学的专家学者共同就新商科建设的途径进行了深入交流,就新商科开放创新实验室的运营模式创新达成共识。各方代表希望上海开源信息技术协会发挥社会组织的职能,尽快落实,积极推动,加快制定参与新商科开放创新实验室建设的规则及机制,早日召开新商科开放创新实验室成立大会。
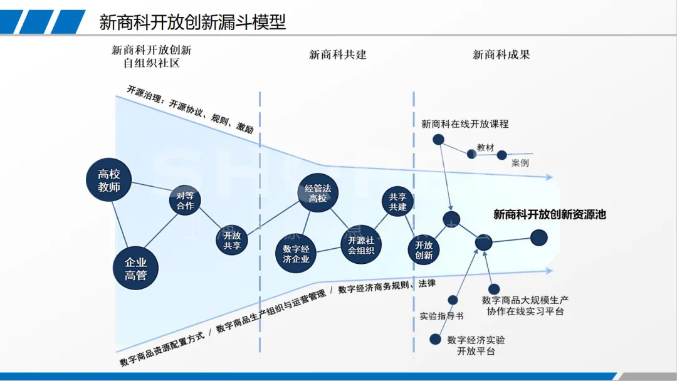
新商科是针对现有商科课程体系、人才培养模式不能适应数字经济发展需要,而现有商科院校难以独自完成自我教育革命的现状而提出来的一个概念。新商科不是在现有课程体系、人才培养模式下运用数字技术而进行的修修补补,而是基于社会需求,在新的教育理念指导下,按照数字经济基本规律,重新构建课程体系、人才培养模式、教学模式、管理体制的过程。
新商科开放创新实验室将采用开源模式,由上海开源信息技术协会负责提供新商科开放创新实验室建设所需要的技术支持、实验指导书、大学生在线实习平台等公共基础设施。基于开放、共享、对等、协作的开源精神,在遵循开源协议的前提下,企业高管、高校老师按照分布式自组织方式参与课程建设、课题研究、实验指导书编写等工作。
开源是数字经济大规模生产协作方式,按照自组织方式运行,具有极强的生命力。
新商科开放创新实验室将就如下课题展开研究:
1. 数字商品资源配置方式;
2. 数字商品生产运营与管理模式;
3. 数字社会秩序与规则。