协会地址:上海市长宁区古北路620号图书馆楼309-313室

介绍 STATE-Bench:一个 AI 代理记忆的基准测试
来源: Microsoft Open Source Blog
作者: Lewis Liu 和 Nishant Yadav
发布时间: 2026/5/20 01:30:00
原文链接: https://opensource.microsoft.com/blog/2026/05/19/introducing-state-bench-a-benchmark-for-ai-agent-memory/
一个衡量记忆在生产环境中为AI智能体带来何种效果的开源基准
所有人都同意,智能体在生产环境中需要记忆。但我们仍缺乏一种有效方法来判断记忆究竟能带来多大帮助。大多数记忆基准只是检索测试:从50轮对话前提取一个名字,或从长对话中浮现一条信息。这只能说明管道工作正常,无法证明智能体表现更优。
这一差距在企业工作流程中至关重要。客户支持智能体崩溃并非因为忘记事实,而是因为搞错了流程——它跳过策略检查、呈现不完整的用户详情、错误或低效地使用领域工具,并不断重复同样的失败模式。
正因如此,我们构建了 STATE-Bench(状态化任务智能体评估基准,Stateful Task Agent Evaluation Benchmark):一个开源、与记忆无关的基准,用于衡量智能体是否能在真实企业任务中通过经验获得提升。今天我们将其免费开放给智能体开发者、研究人员和平台团队。
此次发布覆盖三个领域:客户支持、旅行和购物,包含450个任务,涵盖策略合规、信息综合和多步推理流程。观看Open at Microsoft节目,了解这项工作的动机和幕后人员。
我们聚焦企业场景,因为它们会加剧在生产中看到的那些失败模式。这些任务具有三个共同属性:
- 程序化(Procedural):智能体必须遵循特定领域的程序来执行任务,例如查询预订、验证用户资格、检查策略、计算费用、确认,然后执行。跳过任何一步,结果通常是错误的。
- 有状态(Stateful):企业智能体超越对话聊天;它们会更改数据库中的系统状态(退款记录、预订状态、账户更新)。错误不是糟糕的回答,而是产生实际成本和清理工作。
- 用户体验(User experience):除了任务成功之外,基准还会评估用户与智能体交互的质量。我们制定了详细的评分标准,对以用户为中心的体验应具备何种形态给出了严格指导(参见下方指标部分)。
评估循环
在 STATE-Bench 中,每个任务都是一个独立的场景,包含预填充的数据伪影数据库(如预订、订单、购物车)、一个带有具体问题的客户,以及一组定义成功与否的确定性状态断言。
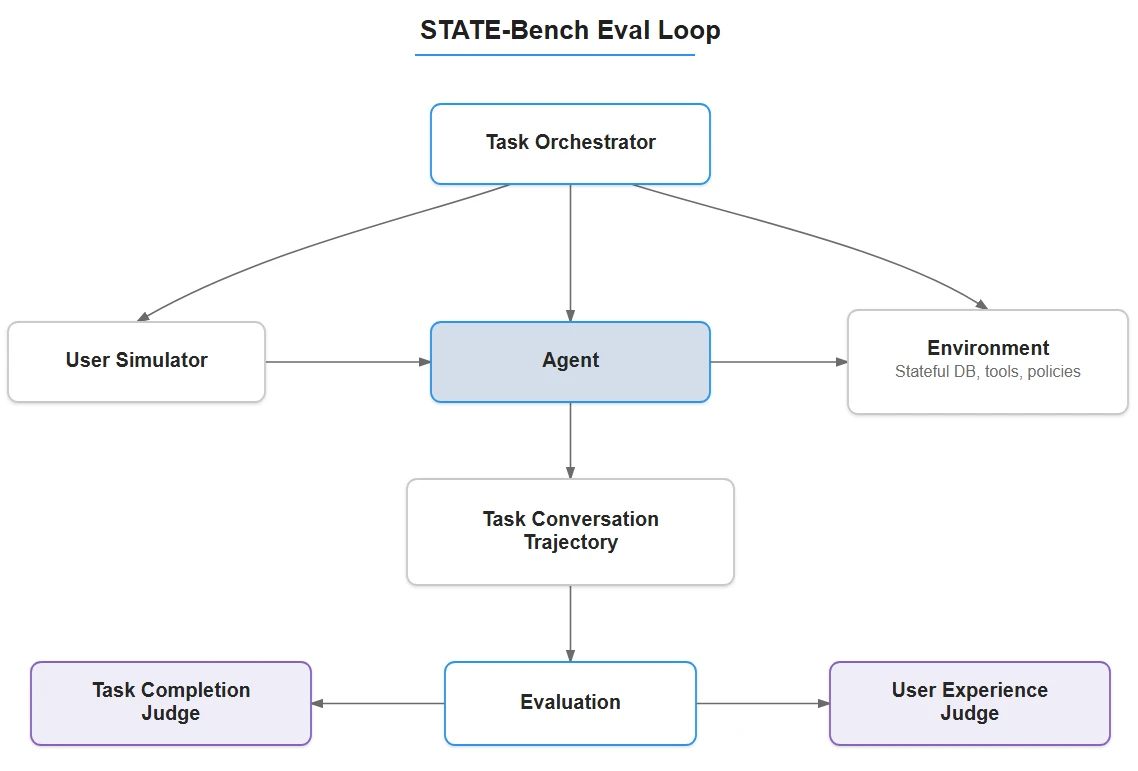
编排器运行一个多轮对话循环。在每一轮中,智能体接收完整的对话历史,并以工具调用和文本形式作出响应。工具在有状态环境中执行:例如查找预订、检查政策,然后用户模拟器自然地作出回应,仅在被问及时才透露信息。循环持续进行,直到任务解决或达到轮次上限。
基于 LLM 的用户模拟器是 STATE-Bench 的核心。它保持用户细节的一致性,在适当时进行追问,并强制智能体收集缺失信息,而不是做出假设。每个模拟器还带有轻量级个性——例如,某个用户可能不耐烦并提供不完整的细节,而另一个用户则一开始就提供所有信息。
为了保持评估的稳定性,模拟器遵循一套详尽且针对特定任务的规则集,且不会超出该规则集进行响应。在测试中,模拟器引发的方差约为 1%,主要来自原始 LLM 的噪音——因此成功或失败反映的是智能体本身,而非模拟器。
生产就绪的严格指标
STATE-Bench 从四个维度评估智能体:是否完成任务、是否在不同运行中一致完成、运行效率如何、以及与用户的交互质量如何。
- 任务完成率: 每个任务运行五次,并报告平均完成率。对于状态变更类任务,确定性评分器将最终环境状态与真实值进行比较。对于流程类和信息类任务,LLM 评判器评估智能体是否遵循了预期流程。
- 智能体可靠性: 报告 pass⁵,即五次运行均成功的任务百分比,用于衡量执行一致性。
- 智能体效率: 衡量完成一个任务的平均成本,包括轮次、不必要的工具调用,以及所有输入、输出和检索 token。
- 用户体验评分: LLM 评判器对完整对话进行用户体验评分,使用 1 到 5 的评分表,涵盖五个维度。例如,用户轻松度衡量用户需要付出的努力,而用户同意度衡量智能体是否在行动前征求确认并呈现选项。
这些指标共同提供了智能体性能的多维视图,涵盖了任务结果、运行一致性、运营成本和交互质量。在此基准测试中,可以对比记忆系统是否与可靠性变化、较难任务的进展、轮次计数和用户体验相关联。
量化记忆差距
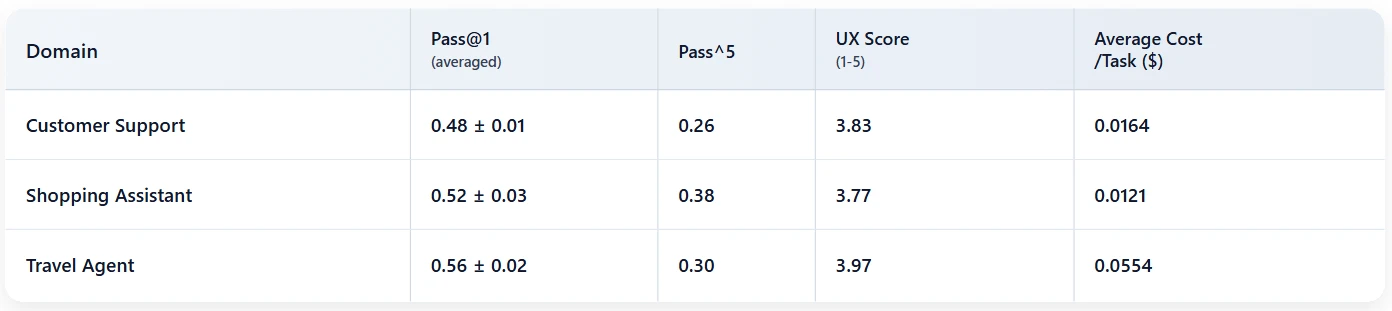
我们使用 GPT-5.1(无记忆)在 STATE-Bench 上建立了基线,跨三个领域每个任务运行五次。尽管有强大的提示设计和完整的工具访问权限,模型仍无法可靠地完成一半以上的任务。pass⁵ 结果尤其具有启发性:在旅行领域,只有约 30% 的任务能在五次运行中全部成功。
平均 Pass@1 与 pass⁵ 之间的差距凸显了核心挑战:即使面对相同任务,智能体也可能表现不一致。我们认为这正是记忆系统旨在缓解的失败模式。
自带记忆系统——一项开放挑战
STATE-Bench 提供了任务、环境、工具、用户模拟器(user simulator)和评分机制。它提供了一套可复现的开放标准,用于回答生产环境中真正重要的问题:我的记忆系统是否让我的智能体(agent)更可靠?它是否减少了完成任务所需的交互轮数?它是否改善了用户体验?现在你不必依赖内部基准测试或逸事性测试,而是拥有一个社区可以共同构建和进行对比的共享框架。
STATE-Bench 面向三类用户:
- 智能体开发者:衡量添加记忆是否能提升智能体的可靠性、任务完成率和效率。
- 研究人员:一个可复现的开放基准,用于比较不同的记忆架构与方法。
- 平台构建者:一个将记忆作为更大智能体栈(agent stack)组件进行评估的框架,并提供可插拔接口来测试你自己的实现。
STATE-Bench 完全开源:
- 涵盖三个领域(旅行、客户支持、购物)的 450 个任务,附带预填充的环境、用户模拟器以及确定性断言(deterministic assertions)。
- 领域无关的评估框架(编排器、评分和指标)。
- 可插拔的智能体接口(自带记忆系统)。
- 任务生成与审计工具,用于验证任务正确性和可解性。
你可以在 GitHub: STATE-Bench 获取它。请给该仓库加星、运行基准测试,并分享你的构建成果。先运行无记忆基线以确定初始水平;然后通过自带记忆接口接入你的记忆系统;对比所有四项指标的测试结果;最后将你的发现分享给社区。

了解如何使用开源基准测试来衡量智能体的改进。

Lewis 正在构建人工智能基础设施的下一个前沿,专注于 Microsoft 的智能体(agents)的存储与图系统。此前,他是 Google Gemini、PaLM2、AutoML 产品的创始产品经理(founding PM)。

Nishant Yadav
高级应用科学家(Senior Applied Scientist)
Nishant 致力于研发能够从过往经验中学习的 AI agents(人工智能代理),重点关注构建真实的代理基准测试。此前,他在微软从事代理式内容理解(agentic content understanding)和自定义大语言模型(custom-LLMs)的训练工作。