协会地址:上海市长宁区古北路620号图书馆楼309-313室

Kubernetes上自主AI基础设施的四大支柱 – 自主AI基础(AAIF)
作者: Max Körbächer
原文链接: https://aaif.io/blog/agentic-ai-infrastructure-on-kubernetes/

Agentic AI(智能体AI)正在重新定义我们刚刚习惯的基础设施标准。
在过去近十年里,“微服务”(Microservice)一直是软件工程中无可争议的价值单元。我们花了数年时间完善无状态、可预测的容器技术,将其包裹在 GitOps 和 CI/CD 管道的层层封装中,以确保昨天部署的内容与明天运行的内容完全一致。但现在,我们正目睹集群中出现一个新的“居民”:自主智能体(Autonomous Agent)。
我们看到的是,我们拥有正确的引擎,却在使用错误的蓝图。Kubernetes 凭借其巨大的可扩展性和硬件抽象能力,仍然是唯一能够承载智能体未来的平台。然而,我们继承的设计模式——即 2022 年的“最佳实践”——正在积极阻碍自主智能体系统的发展。
要真正服务于智能体生态系统,我们必须停止将智能体视为静态的 Web 应用,而开始将它们视为动态的、认知的过程。
可预测性的问题
冲突的核心在于工作负载的本质。传统的 Kubernetes 模式依赖于“期望状态”(Desired State)。人类精确地定义应该运行多少个副本、它们的内存限制是多少、以及它们应该如何通信。相比之下,智能体本质上是非确定性的。它们不仅响应流量,还会生成逻辑、产生子任务,并根据手头目标的复杂性改变自身的需求。
看看像 goose 这样的工具。当 Goose 被分配一个迁移任务时,它不会只是待在那里;它会自主决定调用哪些工具、启动哪些环境。如果 Goose 决定需要一个临时的 Python 环境来处理数据集,它就会去做。我们当前的 GitOps 流程要求人工审核的 PR(Pull Request),在这种情况下就像一堵砖墙。基础设施需要像它所承载的智能体一样敏捷。
我们当前的基础设施将“崩溃”视为需要通过重启来缓解的故障。但在智能体世界中,一个智能体可能会故意启动一个临时环境来测试某个假设,执行生成的脚本,然后将其全部拆除。智能体会引发有意的“不稳定”或“临时执行”,这在传统编排器看来就像是故障。因此,我们当前依赖人工审核的 GitOps——每次基础设施变更都需要一个 Pull Request 和手动合并——已经成为最终的瓶颈。
构建智能体运行时的四大支柱
为了弥合这一差距,基础设施必须演进以提供四种原生能力,这些能力曾经被认为是“锦上添花”,但现在已成为安全和性能的基本要求。
首先,我们必须通过隔离与沙箱化(Isolation and Sandboxing) 来解决安全支柱问题。在智能体 IT 环境中,智能体经常编写并执行自己的代码。当处理自主的、未经审核的执行时,依赖共享主机内核的标准 Docker 容器已不再足够。新的模式要求使用由 Google 捐赠的“Agent Sandboxes”(智能体沙箱),这是一种基于 gVisor/Kata Containers 构建的高性能、临时环境。这使得基础设施能够为智能体的每次工具调用提供硬件级别的隔离,确保“幻觉”脚本或恶意逻辑循环永远不会危及底层节点。
与安全并行的是对有状态记忆结构(Stateful Memory Fabrics) 的需求。我们终于超越了早期 AI 的“无状态原罪”——每次交互都需要在网络上来回传递大量聊天历史。基础设施现在必须提供一个分层的“认知记忆”(Cognitive Memory)层。像 Model Context Protocol (MCP) 这样的项目是第一步。但有状态记忆结构不仅仅是一个或一个数据库;它是一个从用于活跃推理的热本地 KV 缓存,到用于智能体群体的温共享内存,再到冷向量原生存储的结构。也许这甚至需要直接集成到 Kubernetes 存储类中。通过将记忆移入基础设施,我们允许智能体在重启后保持上下文,而无需承受巨大上下文窗口膨胀的开销。
第三个支柱是对动态GPU调度(Dynamic GPU Scheduling) 的彻底重新构想。我们正在进入”突发推理(Bursty Reasoning)”时代。与流量稳定的Web服务器不同,智能体可能因等待外部API而闲置数分钟,然后突然需要大量计算爆发来规划其接下来的十步行动。在这种模式下,静态GPU预留是一种经济灾难。我们需要转向分式vGPU调度(fractional vGPU scheduling)和空间多任务处理(spatial multitasking),让Kubernetes调度器能够根据智能体推理任务的即时”重要性”,实时切片和重新分配计算能力。
最后,我们必须将可观测性即信任(Observability as Trust) 重新定义。在微服务时代,HTTP 200状态码意味着成功。而在智能体时代,智能体可能返回成功码,却完全未能完成其任务。我们需要超越系统日志,进入”推理轨迹(Reasoning Traces)”。通过扩展OpenTelemetry等协议,基础设施需要捕获代码执行过程中的”思维链(Chain of Thought)”,使站点可靠性工程师(SRE)能够监控自主工作力的决策完整性以及每目标成本(cost-per-goal)。
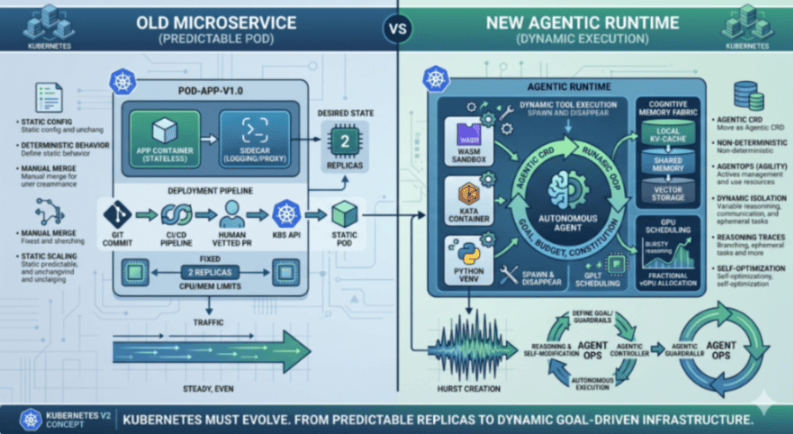
从 GitOps 到 AgentOps:新的内核
这一切引出一个问题:我们是否需要从 GitOps 过渡到 AgentOps?如果 Kubernetes 是智能体操作系统(agentic operating system)的内核,我们就需要一种与之交互的新方式。我们正在从静态清单(static manifests)转向 智能体 CRD(Agentic Custom Resource Definition,自定义资源定义)。
智能体 CRD 不仅仅定义镜像和端口;它定义目标、预算以及一组工具权限。它让基础设施扮演治理者(governor)的角色,而非微观管理者(micromanager)。这需要工程思维发生根本性的、或许令人不适的转变。过去十年,我们的信条是: “它必须在每台机器上以完全相同的方式运行。” 在智能体时代,这转变为: “它将在每台机器上以某种方式工作。”
我们正从 确定性可靠性(Deterministic Reliability)(代码始终以相同方式执行)转向 目标可靠性(Objective Reliability)(目标达成,即使智能体每次走不同的路径)。
但我们必须问自己:我们真的想要这样吗?
拥抱这种“某种方式”,我们获得了巨大的能力和速度,正如在 Goose 等项目中所见——它可以自主修复自身的依赖。但我们也放弃了“冻结”生产环境带来的舒适感。如果一个智能体使用 MCP 拉取实时上下文,然后生成一个独特的 Wasm 沙箱来解决问题,那么没有两次执行会是相同的。我们正在用“已知状态”的安全性换取自主推理的效率。
前进之路
因为我们正在构建更快的模型、更复杂的智能体系统和多样化的工作负载,我们必须构建更智能的运行时。前方的道路要求我们摒弃许多关于“稳定”基础设施的既有认知。我们必须拥抱瞬时性(ephemerality),优先考虑认知状态(cognitive state),并构建能够最终跟上自主思维不可预测性的系统。
Kubernetes 已经赢得了作为平台的战役。现在,或许是时候思考 Kubernetes v2 了。
进一步资源:
- arXiv 2504.19413, “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory” (2025年4月)。向量+图混合;基准测试显示 Mem0 图构建在一分钟内完成,而 Zep 在最坏情况下延迟长达数小时,详见 arXiv。
- arXiv 2507.22925, “Hierarchical Memory for High-Efficiency Long-Term Reasoning in LLM Agents (H-MEM)” (2025年7月)。多层抽象与位置索引编码 arXiv,为分层架构提供了清晰的学术引用。
- arXiv 2506.06326, “Memory OS of AI Agent” (MemoryOS) (2025年6月)。三层 STM/MTM/LPM 架构,采用热度替换策略 arxiv,可直接作为“热/温/冷”参考。
- arXiv 2604.07874, “Valve: Production Online-Offline Inference Colocation” (2026年预印本)。学术支持:生产环境中的 LLM 推理在计算和 KV-cache 内存上都具有突发性;基于 SLA 的峰值配置导致 GPU 平均利用率不足。
- Kubernetes 上游文档 kubernetes.io/docs/concepts/scheduling-eviction/dynamic-resource-allocation/。权威参考,涵盖 ResourceClaim、ResourceClaimTemplate、DeviceClass、可消耗容量(从 40 GiB GPU 中切分 10 GiB)、cloudkeeper 设备绑定条件。
- llm-d 项目 位于 llm-d.ai 和 github.com/llm-d/llm-d。基于 Kubernetes 的分布式推理,使用 vLLM,通过 Gateway API Inference Extension 实现 KV-cache 感知路由,Red Hat 的 P/D 分离。报告称在 8×H100 节点上,TTFT 降低约 3 倍 llm-d,前缀缓存感知路由使吞吐量提升约 2 倍。
- OpenTelemetry 博客, “AI Agent Observability – Evolving Standards and Best Practices” – opentelemetry.io/blog/2025/ai-agent-observability/。OpenTelemetry 目前正在为 CrewAI、AutoGen、LangGraph、Semantic Kernel 制定框架约定。
- OpenTelemetry, “OpenTelemetry for Generative AI”,opentelemetry.io/blog/2024/otel-generative-ai/。原始 SIG 公告;定义了 gen_ai.* 命名空间。
- Langfuse, “AI Agent Observability, Tracing & Evaluation” langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse。行业在 OTel 上的趋同。